
Router tuning in one pass
Router-Tuning is a lightweight recipe for enabling dynamic-depth inference in Transformers. It fine-tunes only router-related parameters, leaving the backbone model frozen.
Compared with full-model dynamic-depth tuning, this keeps adaptation cost low while preserving the efficiency-quality tradeoff needed for deployment.
News
Why Router-Tuning?
Traditional transformers execute a fixed number of layers for every token, wasting computation on easy tokens. Mixture of Depths (MoD) addresses this by dynamically skipping less important computations, but two practical issues remain:
High Training Cost
Existing methods usually tune the whole model, causing expensive full-parameter dynamic-depth adaptation.
Quality Degradation
Aggressive skipping can hurt quality if routing is not well calibrated, especially with higher compute budgets.
Router-Tuning tackles both: it focuses optimization on routing components and introduces routing strategies that better preserve performance-efficiency tradeoffs.
Core Method
1 · Router-Only Fine-Tuning
Tune only router-related parameters instead of full-model updates.
The backbone weights remain frozen, dramatically reducing optimization cost for dynamic-depth adaptation — making it practical for models already fine-tuned on downstream tasks.
2 · Attention-Based Dynamic Depth
Uses attention-based routing granularity (attn_token, attn_sequence) to improve compute and memory efficiency.
Preserves output quality under dynamic-depth execution while enabling flexible deployment at different compute budgets.
Results
Router-Tuning improves the efficiency-quality tradeoff over full-parameter dynamic-depth baselines while keeping routing behavior stable.
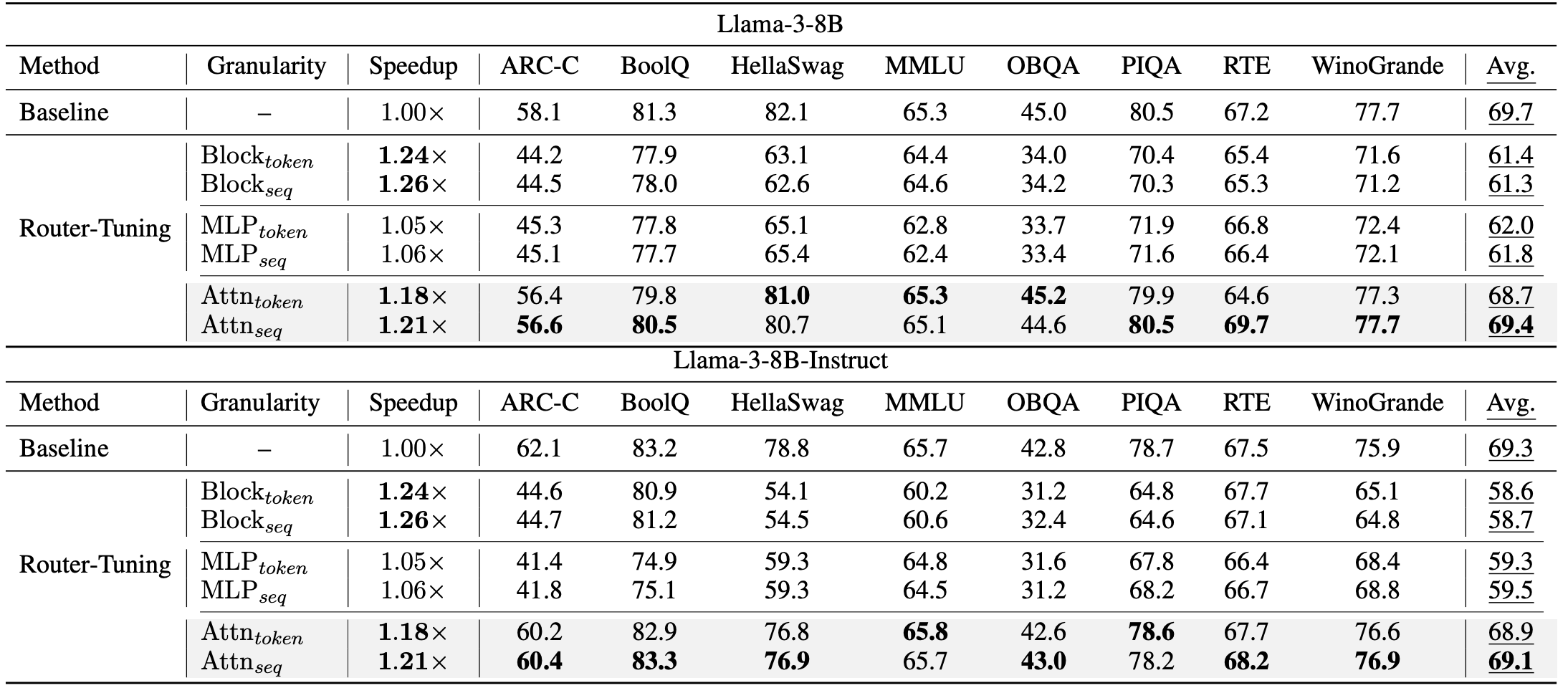
Main Benchmark Results
Router-Tuning achieves strong speedups with small quality degradation across evaluated settings.
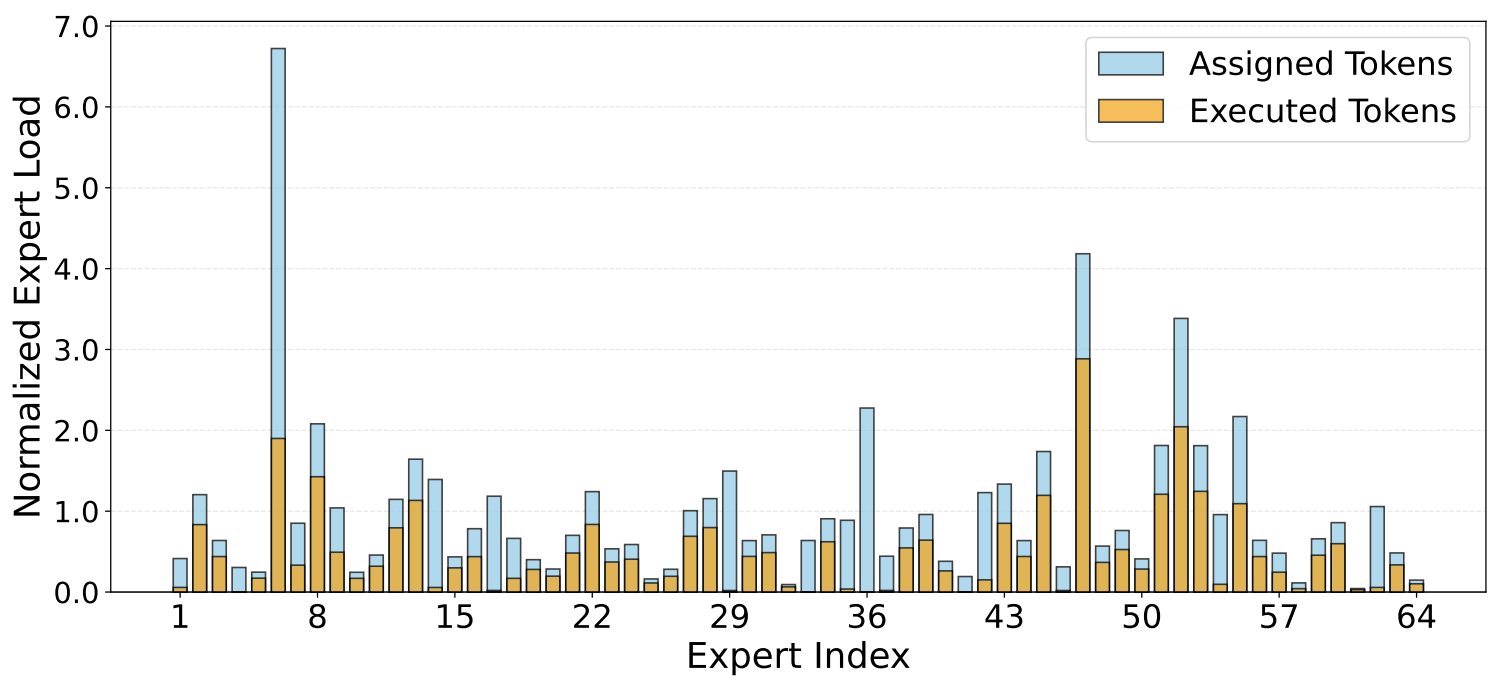
Expert Routing Analysis
Router specialization becomes clearer after tuning: the model learns more stable token-to-layer routing patterns, enabling dynamic-depth execution with lower unnecessary computation.
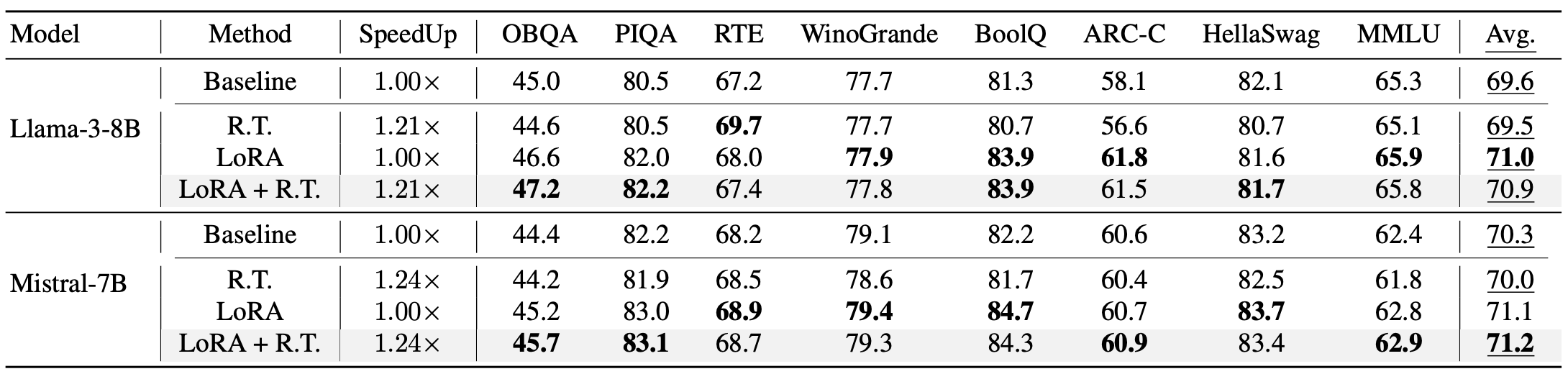
LoRA Compatibility
Router-Tuning composes naturally with LoRA-based adaptation, enabling lightweight deployment recipes without full-model retraining.
Citation
@misc{he2024routertuningsimpleeffectiveapproach,
title = {Router-Tuning: A Simple and Effective Approach
for Enabling Dynamic-Depth in Transformers},
author = {Shwai He and Tao Ge and Guoheng Sun and
Bowei Tian and Xiaoyang Wang and Dong Yu},
year = {2024},
eprint = {2410.13184},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/2410.13184}
}