A few experts receive far more tokens than the average, even when most experts remain lightly loaded.
ICLR 2026
Capacity-Aware Inference
Mitigating stragglers in Mixture-of-Experts inference by placing explicit capacity bounds on overloaded experts, without retraining the model.
1University of Maryland, College Park2The Hong Kong University of Science and Technology (Guangzhou)
30%
MoE-layer speedup on OLMoE with 0.9% degradation
1.85×
end-to-end Mixtral speedup with Expanded Drop
+0.2%
average performance on Mixtral with Expanded Drop

Problem
Expert parallelism waits for stragglers.
Sparse MoE models activate only a subset of experts per token. Under expert parallelism, imbalanced routing overloads a few experts, and every worker waits for those stragglers.
Expert-parallel workers synchronize at the slowest experts, so overloaded experts set the global step time.
The same imbalance appears across language and multimodal sparse MoE settings, making inference-time control useful beyond one model.
Expert-wise imbalance is widespread
Representative capacity profiles show tail-heavy routing across model families.

OLMoE-Instruct

DeepSeek-V2-Lite

Mixtral-8x7B-Instruct
Method
Capacity Bounds for Expert Load
Capacity-Aware Inference bounds expert load with a capacity factor, then either drops overflow tokens or redirects candidates to underused local experts.
\( C = \gamma \bar{N}, \quad \bar{N} = \frac{Tk}{E} \)
\(C\) is the per-expert capacity, \(\gamma\) is the capacity factor, \(T\) is the token count, \(k\) is top-k routing, and \(E\) is the number of experts.

Capacity-Aware Token Drop
Bound each expert by capacity and drop overflow tokens routed to already overloaded experts.

Capacity-Aware Expanded Drop
Expand the candidate expert set toward low-load local experts first, then apply capacity constraints for a stronger throughput-quality tradeoff.
Results
Expanded Drop reduces stragglers losslessly.
Experiments compare baseline routing, Token Drop, and Expanded Drop across language and multimodal MoE models.
A capacity factor limits overloaded experts directly, reducing the synchronization tail.
Overflow tokens can consider additional local experts before being dropped.
The same inference-time control applies to multimodal MoE evaluation.
Efficiency evidence
Speedup and latency breakdowns connect load balancing to wall-clock gains.

Layer-level speedup
Capacity-aware control reduces overloaded expert work across MoE layers.

End-to-end speedup
Capacity-aware inference reduces the wall-clock latency impact of overloaded experts.
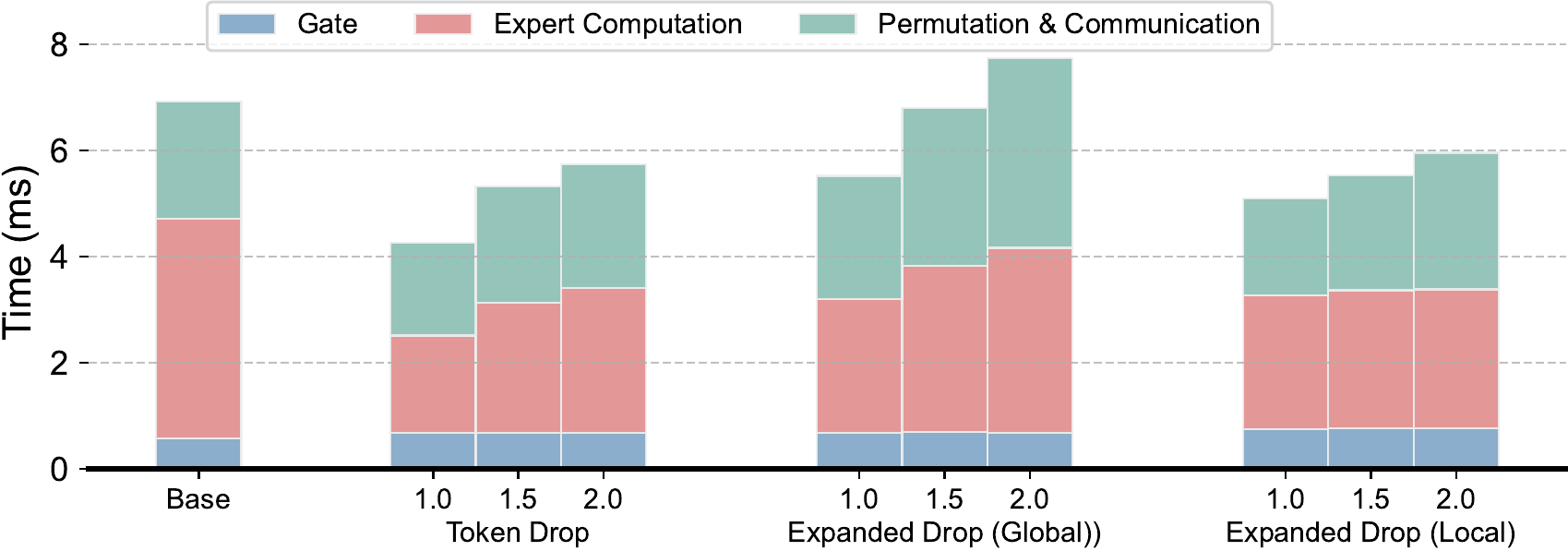
Latency breakdown
Capacity-aware inference reduces expert computation, permutation, and communication time while keeping gate processing comparable.
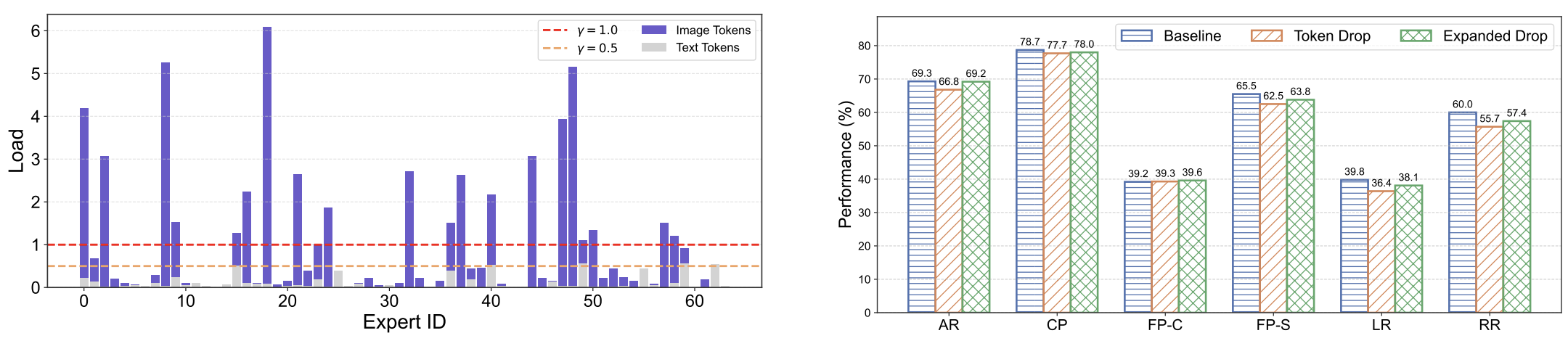
Multimodal applicability
The same inference-time idea transfers to multimodal MoE evaluation.
Resources
Run the evaluation.
The repository includes MoE modeling patches, language evaluation scripts, and a VLMEvalKit multimodal pipeline.
conda create -n capacity-moe python=3.10 -y
conda activate capacity-moe
pip install -r requirements.txt
cd lm-evaluation-harness
bash runs_prune/eval_baseline.sh
bash runs_prune/eval_capacity.shCitation
Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts.
Shwai He, Weilin Cai, Jiayi Huang, Ang Li. ICLR 2026.